 El código genético se conoce como el conjunto de normas almacenadas en el ADN de todo ser vivo existente, se utiliza como modelo para sintetizar cada proteína requerida en la vida. Por lo que el código genético también es un patrón que el organismo contiene con las instrucciones para la nutrición, la reproducción y el crecimiento de las sustancias que lo componen. Dicho material es hallado en el núcleo de las mismas células.
El código genético se conoce como el conjunto de normas almacenadas en el ADN de todo ser vivo existente, se utiliza como modelo para sintetizar cada proteína requerida en la vida. Por lo que el código genético también es un patrón que el organismo contiene con las instrucciones para la nutrición, la reproducción y el crecimiento de las sustancias que lo componen. Dicho material es hallado en el núcleo de las mismas células.
Las instrucciones en el código genético dan paso al ordenamiento en correcta secuencia de los aminoácidos más importantes para la vida, creando cadenas llamadas proteínas, que al mismo tiempo elaboran estructuras mayores o ejecutan funciones indispensables y determinadas.
Cada uno de los seres vivos tiene un código genético, pero no el mismo genoma idéntico. Esto quiere decir que el código no se encuentra ordenado de la misma manera exacta.
Características del Código Genético
Universalidad

Todos los seres vivos conocidos comparten el código genético, sin importar los simples o complejos que sean. Aunque pueden existir discrepancias pequeñas de acuerdo a la especie.
Esto significa que una secuencia de bases nitrogenadas en el interior de un codón específico siempre sintetiza el mismo aminoácido, sin importar que sea un humano o una bacteria.
De esta manera, hay 22 códigos genéticos conocidos en la actualidad, diferentes al código estándar por los datos de uno o varios codones, pero en su mayoría todos son bastantes semejantes.
Continuidad
- Para leer el código genético se hace a manera de ristra de codones, sin puntos, ni comas ni alguna forma de interrupción, en una cadena continua y lineal, en un solo sentido.
- Esto quiere decir que no hay ambigüedad posible para especificar a los aminoácidos porque ninguno puede ubicarse en el lugar de otro distinto en la línea.
- Lo que sí puede suceder es que exista más de un codón al inicio de la cadena, en cuyo caso se podrían sintetizar estructuras múltiples y complejas al mismo tiempo, partiendo de un único y mismo patrón.
Redundancia y especificidad
Todo codón en el código genético, incluyendo la combinación de las tres bases nitrogenadas, es correspondiente de manera exclusiva a un aminoácido puntual. Pero diferentes combinaciones pueden llevar a un resultado en común, por lo que el mismo aminoácido puede estar presentado para dos diferentes codones.
Es importante tener en cuenta esta redundancia para evitar posibles errores al leer el código, debido a que existen más codones posibles que la existencia de aminoácidos.
No existen las superposiciones
Los nucleótidos que componen a un codón no son contenido de otro, de manera que no hay posibilidad de superposición o de leer de nuevo el mismo codón. Esto permite tener una garantía de una lectura unívoca y lineal del código: a manera de tres en tres.
Traducción
El procedimiento de ordenar aminoácidos para la fabricación de proteínas es llamado traducción o síntesis de proteínas. Esto resulta porque el código genético que se encuentra establecido en el ADN se utiliza como modelo para la sinterización de un ARN, que al mismo tiempo es usado como patrón para fabricar proteínas.
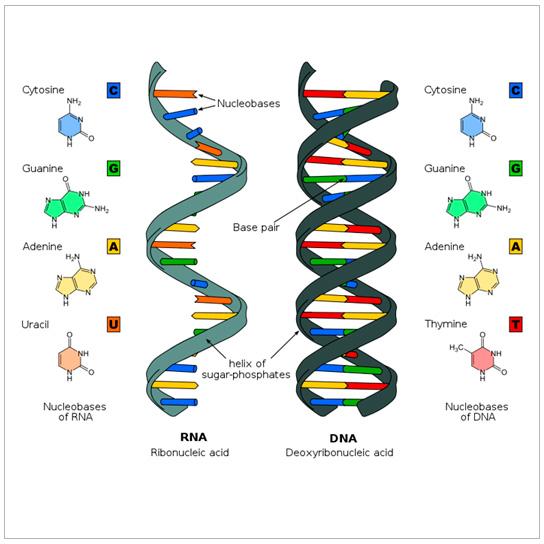
Se define también con el procedimiento de transmitir el mensaje genético desde el ADN hasta el ARN, y desde este hacia un específico orden de aminoácidos. Es realizada a través de las bases nitrogenadas que forman parte del material genético.
Estas son cuatro:
- Timina
- Adenina
- Citosina
- Guanina en el ADN.
Mientras que en el ARN están uracilo, adenina, citosina y guanina. Estas bases nitrogenadas se ordenan en secuencias de 3, a las cuales se les llama codones.
De esta manera, la secuencia de posibles codones del código es igual a 64. Entre estos hay 61 que forman parte de un aminoácido específico, los demás marcan el inicio y el final en la síntesis, como si se tratara de un código morse.
Todo codón es acoplado con un específico aminoácido para garantizar que se ubique en su lugar de la cadena que corresponde a la proteína. Tomando en cuenta el orden, el resultado puede ser una proteína o algo distinto.
Mutaciones
Hay una posibilidad de que mientras se realiza la lectura del código genético, sucedan errores y se produzca una mutación. Esta se define como la inserción por error de un nucleótido en la transcripción del molde primario o ADN al molde secundario o ARN.
Esto puede desencadenar la creación de proteínas disfuncionales, aunque la mayoría de las veces son solo mutaciones silentes que no acarrean daño al desempeño general en el resultado.
Sin embargo, hay ocasiones en las que las mutaciones pueden traer consecuencias catastróficas, haciendo que el ser vivo nazca con enfermedades hereditarias y debilidades congénitas.